Ben MannExploring MAOIs for DepressionI’m considering trying an MAOI (monoamine oxidase inhibitor) instead of my current SNRI (serotonin-norepinephrine reuptake inhibitor) for…3 min read·Mar 5, 2024----
Ben Mann9 lessons from Moral MazesMoral Mazes was written about how large corporate entities worked in the 1980s, but the more things change, the more they stay the same.1 min read·Jan 16, 2022----
Ben MannThe best gift you can givetl;dr: Take 5 minutes to skim https://80000hours.org/key-ideas/. It could be one of the most impactful things you do this year.4 min read·Nov 29, 2020----
Ben MannWhat is utopia?A map of the world that does not include Utopia is not worth even glancing at, for it leaves out the one country at which Humanity is…6 min read·Jul 30, 2020----
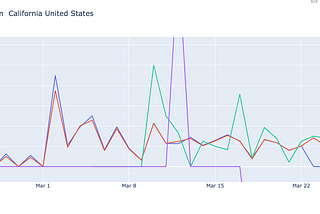
Ben MannCOVID case data explorationIt’s tough to understand all the numbers on COVID developments. I made a Colab notebook to try to answer the question “are things getting…1 min read·Mar 29, 2020----
Ben Mann8 ways to live better“Why didn’t anyone tell me this before??” This is my feeling about most of the content in this list when I first encountered it. I’ve…1 min read·Feb 29, 2020----
Ben MannMy depression and the magic of SSRIsOn Halloween, I started taking Lexapro, an SSRI, to treat my depression. On the first day, I noticed an obvious and immediate effect as…9 min read·Jan 9, 2020--4--4
Ben MannWhy I writeReading about how Leonardo da Vinci journaled so prolifically but only published a tiny fraction made me both sad and inspired. I was sad…6 min read·Jul 2, 2019--1--1
Ben ManninTowards Data ScienceHow to deploy big models500MB of Pytorch on AppEngine and Kubernetes3 min read·Jun 10, 2019--2--2
Ben ManninTowards Data ScienceHow to sample from language modelsCausal language models like GPT-2 are trained to predict the probability of the next word given some context. For example, given “I ate a…6 min read·May 24, 2019--3--3